
Text and pictures by Andreas Herten
Last week, we hosted the first GPU Hackathon of 2017. It was a super intense week full of programming and discussing. It was great coding fun!
The GPU Hackathons (at times also OpenACC Hackathons) are workshop-like events happening around the world. Five of them are planned in 2017 – and the first one was at Jülich Supercomputing Centre last week. Organization is coordinated by Fernanda Foertter from Oak Ridge National Laboratory, who also joins the Hackathons to guide through the week.

A cramped Rotunda
Why one would sit in one large room together with 60 other people and do nothing but group-programming for a whole week you ask? Aren’t LAN parties a thing from the 90s? And, anyway, which map are you playing on?


Well, step back a bit. The basic idea has to do with the following: GPUs, Graphics Processing Units, the things which make computer games look beautiful since a few decades, can also be used for computations which do not have anything to do with graphics. And because Not-only-but-also-GPUs would be bulky and strange, people call this GPGPU, for General-Purpose Computing on GPUs. Using GPUs for arbitrary computing is a huge thing: The processors were made for calculating colors of many pixels of an image at the same time. In parallel. And if an application can make efficient use of these parallel computation pipelines, they might run many times faster. Sometimes orders of magnitude. More science in less time. Because that is awesome, we have a few supercomputers which offer GPU computing possibilities at JSC1. JURECA, for instance, has 75 nodes equipped with Tesla K80 GPUs. Also JURON, a brand-new evaluation machine for the Human Brain Project, features 18 nodes with powerful Tesla P100 GPUs.
GPUs are dedicated devices which must be installed into a computer separately to its central processing unit (CPU). And programs must be adapted specially to use them. Here, the Hackathon comes into play. Teams of GPU experts help teams with scientific applications to either improve their GPU performance or enable them to run on the GPU at all.
Until mid of January, teams with a scientific program could apply for a spot at our Hackathon. They needed to be at least three people and present their program convincingly to the reviewers. At the deadline, we had many more great applications than we thought we would have. So we chose the largest room available at JSC (the Rotunda) and by means of a complicated algorithm (counting floor tiles) determined the maximum number of teams we could accept: Ten. Since every team is paired with their own two expert mentors, we end up with 60 participants in the GPU Hackathon in Jülich. One of the largest workshops which happened in JSC in recent times!2
 The Hackathon started on Monday at 9:00. The first tasks were pretty much set across all teams: Install your application on the supercomputing system, get acquainted to the machine, and find the GPU-eligible hot spots of the program to focus on during the week. The latter is known as profiling and can give great insight into the workings of a program. Luckily, JSC is involved into VI-HPS and we had expert staff members at hand for performance analysis during the week. Very cool (and thanks for that)!
The Hackathon started on Monday at 9:00. The first tasks were pretty much set across all teams: Install your application on the supercomputing system, get acquainted to the machine, and find the GPU-eligible hot spots of the program to focus on during the week. The latter is known as profiling and can give great insight into the workings of a program. Luckily, JSC is involved into VI-HPS and we had expert staff members at hand for performance analysis during the week. Very cool (and thanks for that)!
At the first of the daily mini-presentations on Monday at 15:00, the teams presented their science case and overall plan for the week. For a first time, all participants could get a picture of the diverse science brought to the Hackathon. There were multiple codes simulating quantum chromo dynamics, codes computing atomic structures, different programs caring about the human brain, a project working on a new way to solve mathematical equations e.g. in molecular dynamics, an application solving multi-physics problems, and a program simulating collisions of particles. People came from the US, from Austria, from Japan, and from Germany. Their programs were in C, C++, Fortran, and Python. Some were already mature GPU applications wanting to work on in-detail optimization; some had parts of their code transferred to the GPU but needed expert help in continuing that effort; and some had a full serial CPU code wanting to make the leap of parallelism to the GPU.  The team I mentored, an application reducing the noise of images of the human brain of INM-1, belonged to the latter ones. We decided to work in two sub-groups: Two people wrote the GPU-enabled function for the application’s kurtosis computation; the rest programmed the interface to it.3
The team I mentored, an application reducing the noise of images of the human brain of INM-1, belonged to the latter ones. We decided to work in two sub-groups: Two people wrote the GPU-enabled function for the application’s kurtosis computation; the rest programmed the interface to it.3
The teams were able to run their code on three machines. JURECA, the well-proven, x86-based supercomputer of JSC; JURON, the new system, based on new POWER CPU architecture, but with a very fast GPU and CPU-GPU interconnect; and Piz Daint, the recently upgraded system of the Swiss National Supercomputing Centre (CSCS), offering similar GPUs as used in JURON (P100) but with a x86-based host system (like in JURECA). The teams and their mentors decided on which system to run on (prior experience, benefits of the platform, available tools, …). Piz Daint was used only by some teams to test their application’s behavior on a very (very) large system.
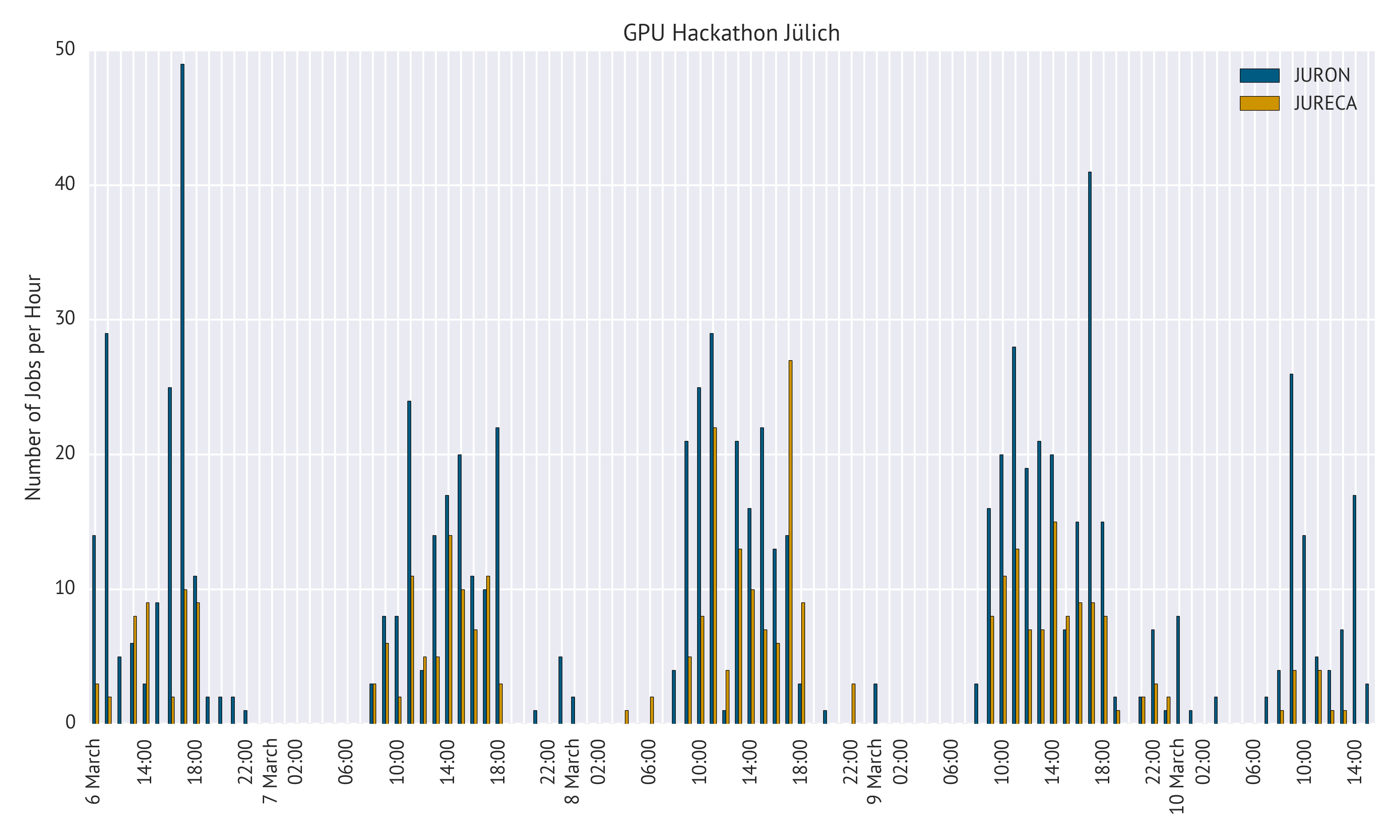
Supercomputer Usage
For the supercomputers in Jülich, I extracted some statistics: In total, over 1000 jobs were submitted during the week. More than ⅔ of those used JURON. Looking at the distribution of jobs over time, one can clearly see the lunch breaks around noon 4 and the late hours spent coding.5





Last year, a GPU Hackathon was hosted in Dresden6. There, we developed a model and terminology to describe the different phases (and code efficiency) during the week. This year, though, showed that the model is not really universal and transferable; our Hackathon was off the chart7. Some groups reached the pit of dispair only at the very last evening when they decided to start over and delete the work they did the previous days; others made already good progress on Monday and steadily increased their GPU performance during the week.
While the teams were programming their code, discussing strategies on whiteboards, and continuously re-optimizing implementations, Fernanda set goals to guide the teams through each working day. Is data accessed in a consecutive, aligned and hence efficient way? Are the data transfers to the GPU devices kept to a minimum? Are they occurring asynchronously to computations on the devices? Can external libraries be used instead of the homegrown function? While those are some of the usual tricks from the grand book of parallel (/GPU) programming, it’s good to dedicate time to them and discuss the options in detail. The intent of the workshop is not only to directly speed-up an application’s runtime, but to also setup the teams for future GPU optimizations on their own. Sustainability in acceleration!





The Hackathon concluded on Friday with a large presentation where everyone summarized the progress they made during the week. The teams presented their successes and challenges, what they started off with and what their GPU plans for the future are. They explained the used technologies, the achieved speed-ups, the strategies which did not work out for them, and what they take away from the workshop. The slides for the final presentations are online, in case you want to take a look. But note that they are usually assembled in quite a hurry8 and might not even make sense without the presenter’s additional spoken notes.
Every team was able to make parts of their code run on the GPU and make the code not suck9, which was one of the goals set at the beginning of the workshop. We had the impression that the teams at this Hackathon were already on a comparable high level when they entered it and only extended upon this during the week. Quite a success!
The teams liked the week working closely together with experts in the field a lot. So did we! I personally found the intense working atmosphere very productive and exciting. And that the person, who implemented this one feature into the GPU compiler, was just one table away. My team was successfully able to launch the GPU-accelerated kurtosis function from their usual workflow in the end, with first lines already programmed to bring even more functionality to the GPU devices. And it didn’t suck!
Let’s hope the next Hackathon is not very far away!

Hackathon Group Picture, source: Forschungszentrum Jülich
- Note: I might not be the most objective person on that topic. My Post-Doc is in the NVIDIA Application Lab where I’m analyzing, porting, and optimizing all kind of scientific applications for the GPU. I like those devices.↩
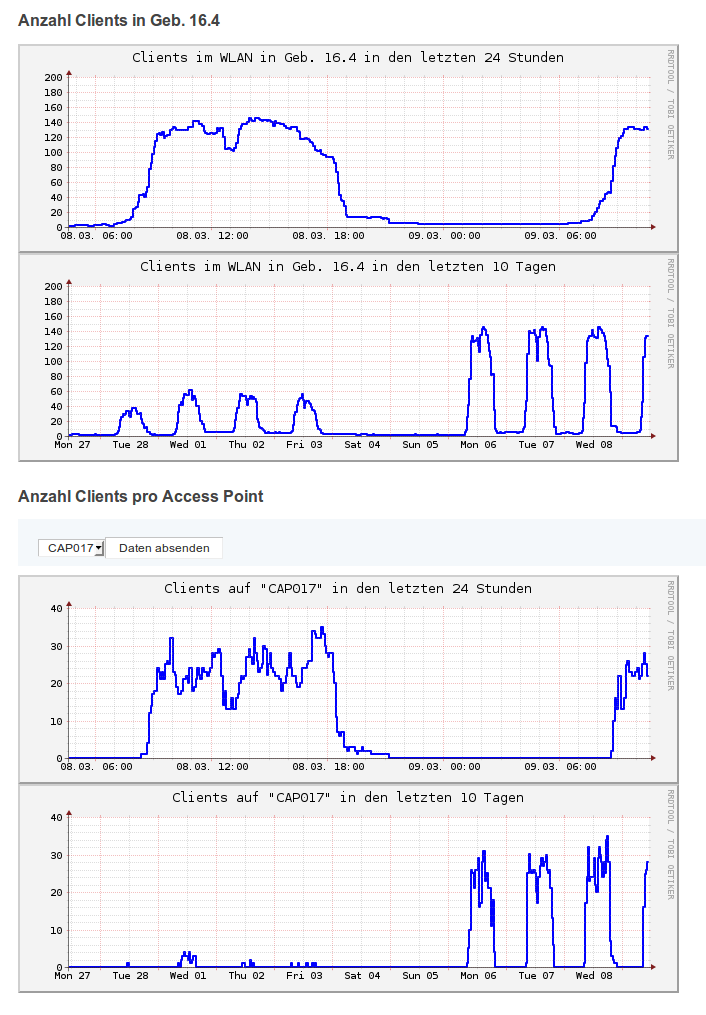
- The colleagues who operate the WiFi hotspots on campus were so kind to provide me with a screenshot of the usage graphs of the relevant hotspots at the mid of the week. We really did put some bits through the air…↩
- The original application is written in Python. We chose to use CUDA C/C++ and OpenACC C to accelerate for the GPU. So, Python needs to talk to the accelerated parts. Hence the interface.↩
- Also hackers need to eat (something but cookies).↩
- Once you’re on a run, it’s just so hard to stop programming in the evening…↩
- Also this year Dresden was heavily involved into the Hackthon. They came over with seven mentors! Thanks for that! And they blogged about the event as well! Go and read their posts for some deeper insights into the challenges of GPU programming.↩
- Sorry for that…↩
- Who wants to create slides when you can also program in that time?!↩
- It doesn’t suck was the catch phrase meaning that the GPU code at the end of the week should run at least a little faster than the original serial version of it.↩
{kind=link}
No Comments
Be the first to start a conversation