Diskutieren Sie mit uns über Künstliche Intelligenz in der Medizin
Zukunftstechnologien finden im Zuge der Digitalisierung mehr und mehr Eingang in die Medizin. Eine Facette von Digitalisierung ist der Einsatz von künstlicher Intelligenz, beispielsweise in der radiologischen Bildgebung. Behandelnde Ärztinnen und Ärzte sowie ihre Patientinnen und Patienten werden dann mit KI-basierten Befunden im Praxisalltag konfrontiert sein.
In einem aktuellen BMBF-geförderten Forschungsverbund gehen wir im Forschungszentrum Jülich der Frage nach, welche Anforderungen Sie an den Einsatz von künstlicher Intelligenz in der radiologischen Diagnostik stellen. Welche Chancen sehen Sie? Welche Bedenken haben Sie?
Zu diesem Zweck suchen wir
ÄRZTINNEN und ÄRZTE in Praxis und Klinik, die sich mit Kolleginnen und Kollegen in wissenschaftlich moderierten Kleingruppendiskussionen austauschen möchten
sowie
BÜRGERINNEN und BÜRGER, die medizinische Gesundheitsleistungen in Anspruch nehmen, wie z.B. haus- oder fachärztliche Behandlung oder Vorsorgeuntersuchungen, und ihre Haltung zum Einsatz von künstlicher Intelligenz mit anderen Bürgerinnen und Bürgern diskutieren möchten.
Ort und Zeitpunkt der Diskussionsrunden werden wir mit Ihnen abstimmen.
Für die Teilnahme erhalten Sie eine Aufwandsentschädigung in Höhe von 100,- €.
Weitere Informationen zu unserer Studie können Sie dem beigefügten Flyer oder unserer Homepage (https://www.fraim-projekt.de) entnehmen.
Über Ihr Interesse und Ihre Anmeldung würden wir uns sehr freuen. Diese können Sie an fokusgruppe@fz-juelich.desenden.
Telefonisch erreichbar für Anmeldung sowie für Rückfragen sind wir unter 02461 – 61 96622 (Katrin Heyl) oder 02461 – 61 2794 (Cornelia Karger).
Alzheimer ist wohl die bekannteste Form der Demenzerkrankungen. Alleine in Deutschland sind etwa 700.000 Personen davon betroffen. Doch wie entsteht eine Alzheimer Erkrankung eigentlich und wie kann sie diagnostiziert werden?
Wie entsteht Alzheimer?
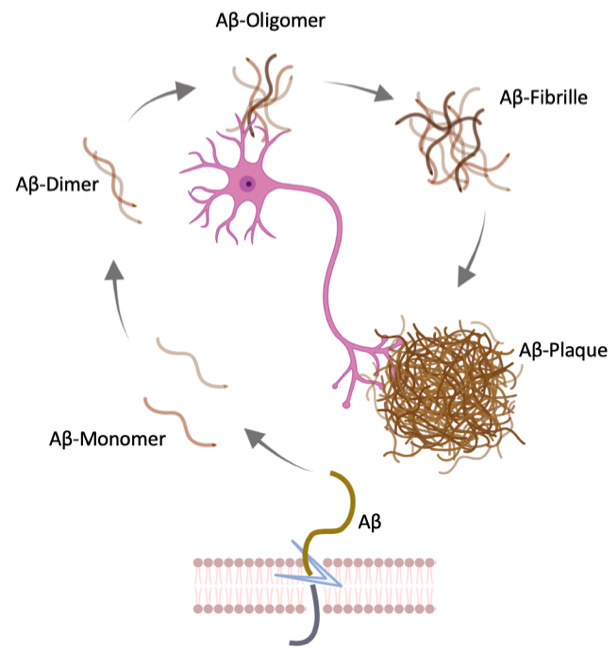
Die Alzheimer Krankheit ist eine neurodegenerative Erkrankung, die durch das kontinuierliche Absterben von Nervenzellen des Gehirns gekennzeichnet ist. Auslöser dafür ist der Zusammenschluss mehrerer gleicher Einzelbausteine. Diese Einzelbausteine, die sogenannten Amyloid-beta Monomere (Aβ), sind Eiweißfragmente, die ständig während unseres gesamten Lebens bei der Spaltung eines bestimmten Eiweißes freigesetzt werden. Diese einzelnen Aβ-Monomere sind ungefährlich und in jedem Menschen vorhanden. Bei der Alzheimer Erkrankung wird jedoch vermehrt Aβ gebildet, welches nicht schnell genug wieder abgebaut werden kann. Der Überschuss an Aβ-Monomeren hat zufolge, dass sich mehrere dieser Einzelfragmente außerhalb der Nervenzellen zu größeren toxischen Komplexen, den sogenannten Aβ-Oligomeren verbinden. Mit fortschreitender Erkrankung bilden diese Komplexe stabile Verbindungen und entwickeln sich schließlich zu den bekannten Alzheimer-Plaques (siehe Bild 1).
Neuere Studien zeigen jedoch, dass die Aβ-Oligomere die zentralen Treiber des Krankheitsgeschehens sind. Sie lagern sich zwischen den Nervenzellen ab und stören so deren Kommunikation, was letztlich zum Absterben der Nervenzellen führt. Infolgedessen nimmt das Hirnvolumen mit fortschreitender Erkrankung immer weiter ab – d.h. das Gehirn schrumpft.
Bild 1. Hier ist die Entstehung von Aβ-Plaques schematisch dargestellt. Bei der Spaltung eines bestimmten Eiweiß wird ein Eiweißfragment, das sogenannte Aβ freigesetzt. Ein solches Einzelfragment wird als Aβ-Monomer bezeichnet – diese sind harmlos und in jedem Menschen vorhanden. Bei Alzheimer Patient:innen wird jedoch vermehrt Aβ gebildet, welches nicht schnell genug wieder abgebaut werden kann. Somit verbinden sich einzelne Aβ-Monomere zuerst zu Aβ-Dimeren, danach zu Aβ-Oligomeren, anschließend zu Aβ-Fibrillen und schließlich zu unlöslichen Aβ-Plaques. Diese Zusammenschlüsse lagern sich zwischen den Nervenzellen ab und stören somit ihre Informationsweitergabe.
Diese krankhaften Veränderungen des Nervensystems finden schon ganz zu Beginn der Erkrankung statt und wirken sich oft erst nach 5-10 Jahren schrittweise auf das Verhalten der Patient:innen aus. Die ersten äußerlich sichtbaren Symptome sind dann durch Störungen des Kurzzeitgedächtnisses geprägt. Infolgedessen haben die Betroffenen Schwierigkeiten, sich Informationen zu merken und Gesprächen zu folgen. Im weiteren Verlauf der Erkrankung wird auch das Langzeitgedächtnis beeinträchtigt, sodass vergangene Ereignisse und Erlebnisse nicht mehr abgerufen werden können. Auch die räumliche und zeitliche Orientierung nimmt immer weiter ab, weshalb Patient:innen auf Betreuung und Unterstützung bei der Alltagsbewältigung angewiesen sind. Diese Entwicklung geht sogar so weit, dass Patient:innen im Endstadium körperlich immer weiter abbauen und Schwierigkeiten mit dem Sprechen, der Atmung und dem Schlucken haben.
Diagnose
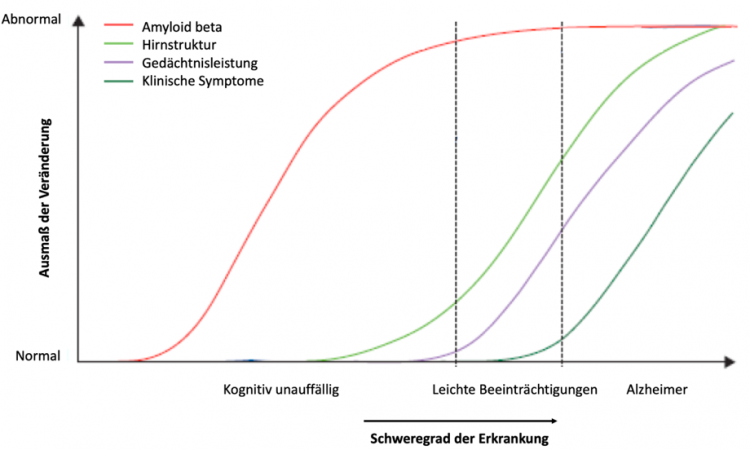
Obwohl Alzheimer bisher noch nicht heilbar ist, gibt es Medikamente, die einige Symptome abschwächen können, jedoch mit Nebenwirkungen einhergehen und den Krankheitsverlauf nicht verlangsamen. Falls es hoffentlich bald wirksame Medikamente geben sollte, die den Krankheitsverlauf verlangsamen können, dann wäre es umso besser, je früher mit der medikamentösen Behandlung begonnen wird. Eine frühe Diagnose ist also sehr wichtig! Das Problem ist aber, dass die Erkrankung häufig erst bemerkt und diagnostiziert wird, wenn anfängliche Verhaltensänderungen klinisch auffällig werden. Zu diesem Zeitpunkt liegt der Beginn der Erkrankung jedoch schon Jahre zurück, in denen es bereits zu massiven Veränderungen im Gehirn gekommen ist (siehe Bild 2).
Zudem sind Symptome wie Vergesslichkeit und Antriebslosigkeit ebenfalls typische Kennzeichnen anderer Erkrankungen, sodass Alzheimer im Anfangsstadium nur anhand äußerlich wahrnehmbarer Anzeichen kaum eindeutig diagnostiziert werden kann. Der Blick auf das Verhalten der Erkrankten alleine reicht also nicht für die frühe Erkennung der Alzheimer-Demenz. Dies hat Dr. Nils Richter in einem Video sehr anschaulich erklärt.
Bild 2. Hier ist das Ausmaß der stattfindenden Veränderungen im zeitlichen Verlauf der Alzheimer Erkrankung dargestellt. Es fällt auf, dass die Konzentration von Amyloid-beta rasch ansteigt und noch vor dem Auftreten erster Symptome bereits auf dem Höhepunkt ist. Dies macht sich etwas später auch in der Hirnstruktur bemerkbar – das Gehirn schrumpft. Erst nachdem es bereits zu massiven Hirnveränderungen gekommen ist, werden die Verhaltensänderungen klinisch auffällig. Zu diesem Zeitpunkt sind jedoch möglicherweise schon irreparable Schäden entstanden, sodass eine medikamentöse Behandlung zur Verlangsamung des Krankheitsverlaufs oft nicht mehr anschlägt.
Deshalb ist die Suche nach relevanten körperlichen Frühwarnzeichen, den sogenannten Biomarkern, besonders wichtig für die Frühdiagnose. Als Biomarker bezeichnen wir biologische Merkmale, wie beispielweise spezielle Blutwerte oder die Körpertemperatur, die auf normale oder krankhafte körperliche Prozesse hindeuten. Zusätzlich zu den Biomarkern werden verlässliche Methoden benötigt, mit denen diese quantifiziert werden können, um die Schwere der Erkrankung zu bestimmen. Wissenschaftler:innen des Forschungszentrums Jülich verfolgen derzeit verschiedene Ansätze zur Erforschung verschiedener Biomarker der Alzheimer Erkrankung, von denen zwei im Folgenden vorgestellt werden.
Fahndung in Körperflüssigkeiten
Wie oben bereits beschrieben, wird die Anreicherung mehrerer einzelner Aβ-Monomere zu größeren Aβ-Oligomeren als Auslöser der Alzheimer Erkrankung angesehen. Da das Auftreten der Oligomere eines der frühesten Vorzeichen sein könnte, konzipierten die Wissenschaftler:innen des Instituts für Biologische Informationsprozesse (IBI-7) einen Test, mit dem diese Oligomere in Körperflüssigkeiten wie Blut oder Hirnwasser nachgewiesen werden sollen.
Die Entwicklung des Tests stellte die Forscher:innen jedoch vor zwei wesentliche Herausforderungen, die es zu lösen galt. Da Aβ-Oligomere aus mehreren Monomeren bestehen, muss gewährleistet werden, dass die Methode präzise zwischen diesen beiden Formen unterscheiden kann, damit ausschließlich die toxischen Oligomere identifiziert werden. Zum anderen muss das Verfahren besonders sensitiv sein, um bereits kleinste Mengen erkennen zu können.
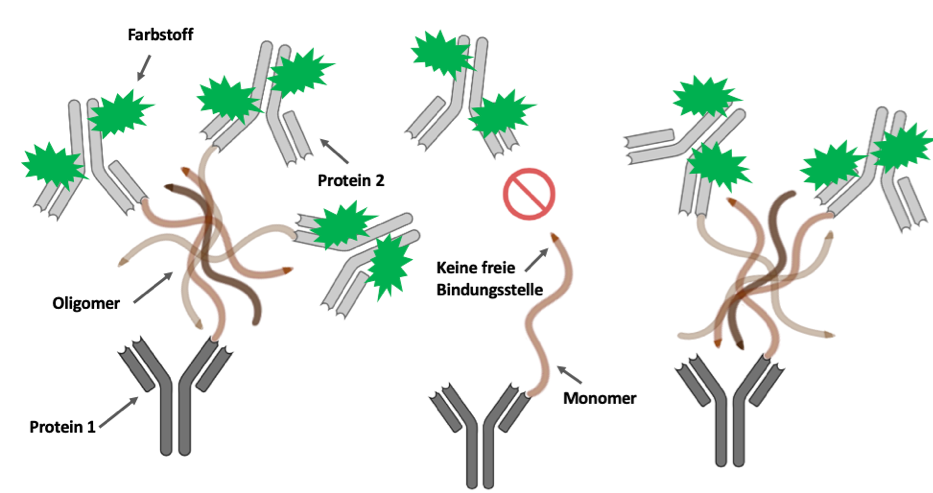
Der Ablauf der sogenannten sFIDA („surface-based fluorescence intensity distribution analysis“) Methode ist schematisch in Bild 3 und in Video 1 dargestellt. Zunächst wird die zu untersuchende Probe auf eine Glasplatte gegeben, auf der sich bereits ein bestimmtes Protein (Protein 1) befindet. Dieses Protein bindet an eine ganz bestimmte Stelle des Aβ (Schlüssel-Schloss-Prinzip). So bleiben nur die Aβ-Oligomere und Monomere auf der Glasplatte zurück und werden infolgedessen von anderen in der Probe enthaltenen Partikeln getrennt.
Als Nächstes wird ein weiteres Protein (Protein 2), welches mit einem Farbstoff (grüne Sterne) markiert ist, zu der Probe hinzugefügt. Dieses bindet an dieselbe Stelle wie das Protein im vorherigen Schritt und macht somit nur die Aβ-Oligomere sichtbar. Der Grund: Monomere besitzen nur eine einzige Bindungsstelle. Diese ist jedoch schon durch das erste Protein blockiert, was eine weitere Bindung mit dem neu hinzugefügten Protein verhindert. Da Oligomere jedoch aus mehreren Monomeren bestehen, haben sie noch freie Bindungsstellen an die das eingefärbte Protein andockt und sie somit „farblich markiert“. Durch den Farbstoff werden diese Verbindungen anschließend unter einem speziellen hochauflösenden Mikroskop sichtbar gemacht. Die Farbintensität ist dabei von der Anzahl der Eiweißverbindungen abhängig. Das heißt, große Oligomere, die viele Bindungen aufweisen, kommen dabei besonders deutlich zum Vorschein.
Bild 3. Hier wird das Verfahren des sFIDA Methode grafisch dargestellt. Das in der Probe enthaltenen Aβ (braune wellenförmige Symbole) bindet an ein bestimmtes Protein (dunkelgraue Y-Symbole) und wird von diesem „festgehalten“. Anschließend werden weitere Proteine (hellgraue Y-Symbole), die mit einem Farbstoff (grüne Sterne) markiert sind, hinzugegeben. Diese binden sich nur an die Bindungsstellen der Oligomere (Ansammlung von braunen wellenförmigen Symbolen) und machen diese durch die Einfärbung unter dem Mikroskop sichtbar. Da die Bindungsstelle der Monomere (einzelne braune wellenförmige Symbole) bereits durch das erste Protein blockiert wurden, binden sie nicht an das neu hinzugefügte Protein. Somit werden nur die Oligomere durch die Einfärbung unter dem Mikroskop sichtbar gemacht. Video 1. Hier wird die Durchführung der sFIDA Methode demonstriert.
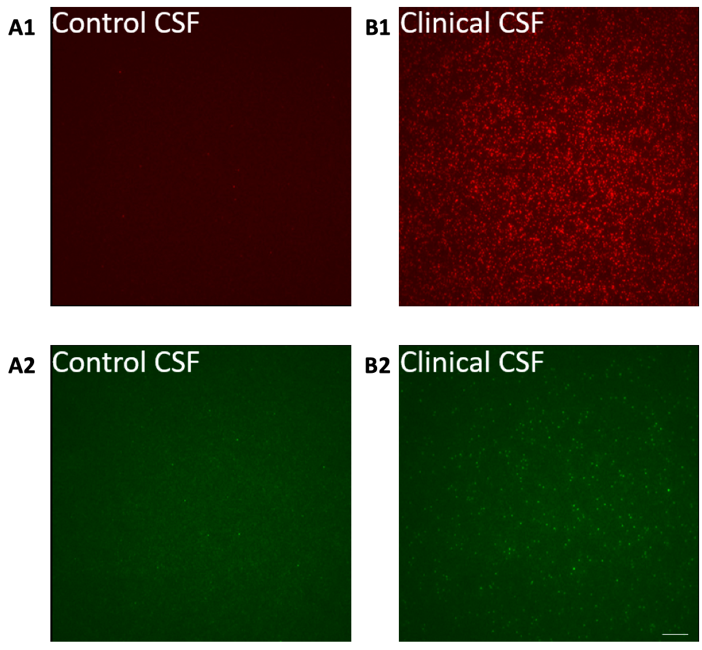
In mehreren Studien wurde bereits gezeigt, dass in Proben von Alzheimer Patient:innen wesentlich mehr Aβ-Oligomere nachgewiesen werden, als bei gleichaltrigen gesunden Personen (siehe Bild 4). Außerdem wurde ein direkter Zusammenhang zwischen dem Ausmaß der kognitiven Beeinträchtigung und der Anzahl der gemessenen Oligomere festgestellt. Das heißt, je schlechter es um die Kognition eines:r Patient:in bestellt war, desto mehr Oligomere befanden sich in den Proben.
Doch was bedeutet das genau? Zum einen wissen wir dadurch, dass anhand der gemessenen Oligomer-Konzentration zwischen Alzheimer Patient:innen und Kontrollpersonen unterschieden werden kann. Die sFIDA Methode könnte also ein vielversprechendes Instrument in der Alzheimer Diagnostik sein. Darüber hinaus scheint die Anzahl der gemessenen Oligomere mit fortschreitender Erkrankung immer weiter zu steigen. Somit würden bereits das Vorhandensein kleinster Mengen ein frühes Vorwarnzeichen einer beginnenden Alzheimer Erkrankung widerspiegeln.
Bild 4. In diesen Mikroskopaufnahmen sieht man die die farbliche Markierung von Oligomeren in Hirnwasserproben von Kontrollpersonen (A) und Alzheimer Patient:innen (B) anhand von zwei verschiedenen Farbstoffen (rot und grün). Es fällt deutlich auf, dass die Konzentration der Oligomere in der Probe der Patient:innen im Vergleich zur Kontrollperson wesentlich höher ist.
Diese Erkenntnisse sind von zentraler Bedeutung für die Medikamentenforschung. Man weiß jetzt, dass die Anreicherung von Aβ-Monomeren zu größeren Komplexen, den Aβ-Oligomeren, den Krankheitsprozess auslöst und vorantreibt und hat eine verlässliche Methode gefunden, diese frühzeitig nachweisen zu können. Damit ist auch das Zielmolekül bekannt, auf das eine geeignete Therapieform ausgerichtet sein muss. Wissenschaftler:innen des IBI-7 haben deshalb erstmals einen besonderen Wirkstoff entwickelt, der gezielt die toxischen Aβ-Oligomere zerstört und diese wieder in ungefährliche Aβ-Monomere zerlegt. Erste Tests verliefen bereits vielversprechend. Nun wird der Therapieansatz in einer Tochterfirma weiter erforscht.
Bildgebende Biomarker
Ein anderer Ansatz zur Früherkennung wird am Institut für Neurowissenschaften und Medizin (INM-7)erforscht. Wie bereits oben beschrieben, kommt es bei der Alzheimer Erkrankung noch vor dem Auftreten klinischer Symptome zu einem vermehrten Verlust von Gehirnsubstanz. Mit dem Magnetresonanztomografen (MRT) können Schnittbilder des Gehirns erzeugt und so Gewebeabbau und Veränderungen der Hirnstruktur entdeckt werden. Allerdings sind diese Hirnveränderungen selbst für eine*n erfahrene*n Radiolog:in im frühen Stadium der Erkrankung nur sehr schwer zu erkennen.
Auch das gesunde Gehirn unterliegt im Laufe des Lebens gewissen Alterungsprozessen. Diese sind jedoch im Vergleich zu denen der Alzheimer Erkrankung erheblich schwächer und in anderen Bereichen des Gehirns ausgeprägt. Dadurch könnten Unterschiede des regionalen Hirnvolumens ein frühes Anzeichen einer Erkrankung sein. Wissenschaftler:innen des INM-7 entwickeln derzeit innovative Ansätze des maschinellen Lernens (d.h. Algorithmen), mit denen frühe Alzheimer-typische Hirnveränderungen identifiziert werden können, die für das menschliche Auge nicht sichtbar sind.
Hierfür nutzen sie die Hirnscans von mehreren Hundert gesunden und an Alzheimer erkrankten Personen. Anhand dessen bestimmen die Wissenschaftler:innen das individuelle Volumen von über 100 Hirnregionen – und das für jede einzelne Person. Das Ziel der Vorgehensweise ist, dass ein Algorithmus nur anhand dieser Volumenangaben den Gesundheitsstatus (d.h. ob eine Alzheimer Erkrankung vorliegt oder nicht) einer Person erkennen soll.
Dazu wird der Algorithmus sowohl mit den Bildgebungsdaten (d.h. das individuelle Volumen jeder einzelnen Hirnregion) als auch mit der Zielvariable, die später vorhergesagt werden soll (d.h. liegt eine Alzheimer Erkrankung vor oder nicht) vieler Personen „gefüttert“, um zunächst in mehreren Trainingsrunden unterliegende Muster oder Zusammenhänge in den Daten zu erkennen. Der Algorithmus wird so trainiert und weiterentwickelt, dass er fähig ist, anhand dieser Trainingsdaten allgemeingültige Zusammenhänge und Regeln aufzustellen, die auf neue Personen übertragbar und anwendbar sind.
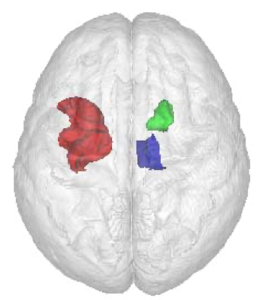
Bemerkenswert war, dass der entwickelte Algorithmus in 91% der Fälle den Gesundheitszustand einer Person nur anhand ihres Hirnscans korrekt klassifizieren konnte. Es hat sich herausgestellt, dass das gemeinsame Zusammenspiel der Volumina verschiedener Hirnregionen für die korrekte Bestimmung des Gesundheitsstatus entscheidend ist (siehe Bild 5). Dieses Vorgehen scheint also Muster in den Hirnscans von Alzheimer Patient:innen zu identifizieren, die für das menschliche Auge nicht sichtbar sind. So könnten beginnende Alzheimer-typische Veränderungen in der Hirnstruktur wesentlich früher erkannt werden.
Bild 5. Die kombinierte Betrachtung der Volumina dreier Gehirnregionen (hier in rot, blau und grün) konnte die Vorhersagegenauigkeit des Gesundheitsstatus einer Person erheblich verbessern.
Das Ziel der Wissenschaftler:innen des INM-7 ist es, dieses Verfahren weiter zu entwickeln und dessen Genauigkeit zu verbessern, damit es zukünftig als zusätzliches Diagnoseverfahren Anwendung in der klinischen Praxis findet. Gegenüber der aufwendigen und zeitintensiven Diagnosemethoden, die gegenwärtig zum Einsatz kommen, vereinfacht die Nutzung modernster Algorithmen diesen Prozess erheblich. Die Auswertung eines Hirnscans mithilfe des Algorithmus ist unkompliziert und soll nur wenige Minuten dauern. Diese erhebliche Zeitersparnis ist ein klarer Vorteil, von dem sowohl der / die behandelnde Kliniker:in als auch der / die individuelle Patient:in profitiert. Eine Untersuchungsmethode, die wenig Aufwand und Zeit in Anspruch nimmt, stellt eine geringere Belastung dar als die herkömmlichen langwierigen Untersuchungen verschiedener Fachärzt:innen. Dadurch könnte die Hemmung bereits bei ersten Anzeichen eine:n Arzt:in zur Abklärung aufzusuchen, gemildert und eine Alzheimer Demenz früher erkannt und behandelt werden.
Fazit
Eine möglichst frühe Erkennung einer vorliegenden Alzheimer Demenz ist wichtig. Nur so können rechtzeitig wichtige Maßnahmen ergriffen und medikamentöse Behandlungen zur Verlangsamung des Krankheitsprozesses eingeleitet werden. Allerdings stellt dies derzeit noch gewisse Herausforderungen dar. Verhaltensänderungen werden oft erst auffällig, nachdem es bereits zu beträchtlichen Hirnschäden gekommen ist. Es braucht also Biomarker und Methoden, um diese zu quantifizieren, damit körperliche Veränderungen, die mit einer beginnenden Alzheimer Demenz einhergehen, schon vor dem Auftreten erster äußerlicher Symptome nachgewiesen werden können. Wissenschaftler:innen des Forschungszentrums Jülich verfolgen dabei verschiedene Ansätze. Studien zur Untersuchung von Körperflüssigkeiten und Hirnscans zeigten bereits vielversprechende Resultate. Das Ziel ist es, diese Verfahrensweisen nun weiterzuentwickeln und zu verbessern, damit diese in Zukunft in der klinischen Anwendung den Diagnoseprozess unterstützen können. Befunde sollen so schnell und unkompliziert sein und dadurch die Ängste und Hemmungen der Patient:innen lindern. Denn schließlich steht das Wohl der Patient:innen immer an erster Stelle.
Hinweis: Weitere Beiträge zur Alzheimer Forschung finden Sie unter:
In den letzten Jahren hat sich im medizinischen Forschungsbereich der Trend etabliert, populations-basierte Studien mit einer sehr großen Anzahl an Versuchspersonen durchzuführen. Je mehr Probanden untersucht werden, desto mehr Daten stehen den Forschern für ihre Analysen zur Verfügung. Das ist die Voraussetzung um Fragen wie „welchen Einfluss hat der Lebensstil auf die Gesundheit“ oder „welchen Zusammenhang gibt es zwischen der Genetik und bestimmten Erkrankungen“ erforschen zu können. Deshalb gibt es weltweit viele Konsortien, die darauf abzielen, möglichst große und repräsentative Stichproben zu erheben, um besonders gut gesicherte Rückschlüsse und Zusammenhänge im Bereich der Gesundheitsforschung ziehen zu können. Den größten Gesundheitsdatensatz stellt die britische UK Biobank Kohorte dar, die in den vergangenen Jahren gesundheitsbezogene Daten von 500.000 Probanden im Alter von 40 bis 69 Jahren erhoben hat, um neue wissenschaftliche Erkenntnisse über häufige und lebensbedrohliche Krankheiten – wie Krebs, Herzerkrankungen und Schlaganfall – zu gewinnen und so die Gesundheit der Bevölkerung zu verbessern. Zusätzlich werden seit 2014 von prospektiv 100.000 Probanden dieser Stichprobe unter anderem Magnetresonanztomographieaufnahmen des Gehirns, des Herzens und des Abdomens erstellt. Solche umfassenden Datensätze, die Forschern weltweit zugänglich gemacht werden, ermöglichen es, die Auswirkungen verschiedener Einflüsse auf die Entwicklung unterschiedlichste Erkrankungen genauer zu beleuchten.
Obwohl dieser Trend sehr förderlich ist, stellen die Speicherung und Verarbeitung dieser enormen Datenmengen die Forscher auch vor komplexe Probleme. Die erste Schwierigkeit betrifft die Beschaffung der Daten. Das Herunterladen der Daten aus einer Cloud würde Wochen oder sogar Monate dauern, weshalb sie häufig auf großen Festplatten gespeichert und per Kurier verschickt werden.
Wenn die Forscher die Daten endlich erhalten haben, besteht die nächste Herausforderung darin, einen Computer zu finden, der den Anforderungen der Speicherung gerecht wird. Sogar hochrangige Supercomputer könnten entweder mit dem benötigten Speicherplatz oder der Anzahl der abzuspeichernden Dateien überfordert sein. Wenn ein Datensatz die rechnergestützten Kapazitätsgrenzen in unterschiedlichen Dimensionen überschreitet, erschwert dies die Prozessierung ungemein.
Eine weitere Anforderung an die Wissenschaft ist, dass Forschungsergebnisse besonders reproduzierbar, also wiederholbar und vertrauenswürdig sein sollen. Erst wenn eine Replikationsstudie die Berechnungen einer anderen Studie wiederholt und zu ähnlichen bzw. gleichen Ergebnissen kommt wie die Erst-Studie, erlangt diese Glaubwürdigkeit. Das ist allerdings bei großen Datensätzen besonders schwierig, da sie oft besonders strengen Datenschutzbestimmungen unterliegen und sie dadurch nicht ohne Weiteres mit anderen Forschern geteilt werden dürfen. Zudem sind viele der gängigen Softwaretools nicht öffentlich zugänglich, weshalb sie nicht jedem Wissenschaftler zur Verfügung stehen, was wiederum die Replikation von Studien erschwert.
Zusammenfassend werden Wissenschaftler bei der Analyse umfangreicher Datensätze mit einigen Herausforderungen konfrontiert. Die Beschaffung der Daten ist bereits relativ aufwendig. Zudem können die Anforderungen des Datensatzes die Hardware überfordern, weshalb ein Computer gefunden werden muss, der leistungsfähig genug ist und diesem Bedarf gerecht wird. Die nächste Schwierigkeit besteht darin, die Ergebnisse überprüfbar und transparent darzulegen, sodass andere Forscher die durchgeführten Analyseschritte nachvollziehen und sie wiederholen können, um die Ergebnisse zu verifizieren.
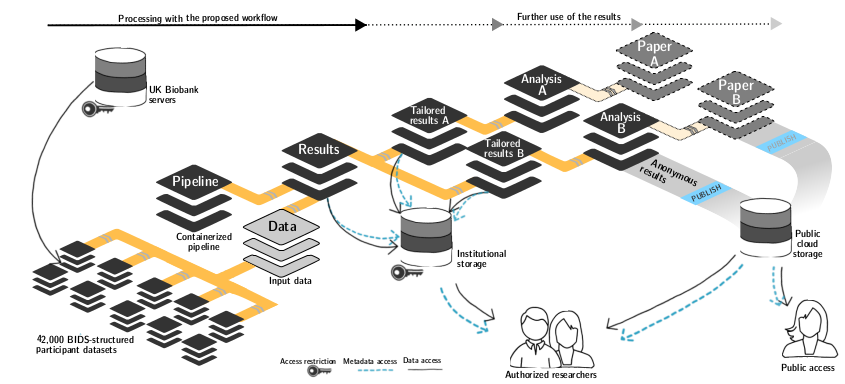
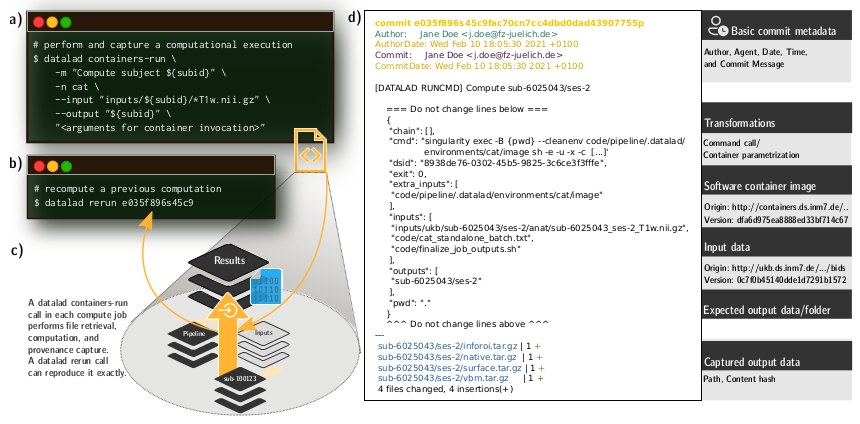
Um dafür eine Lösung zu finden, haben Kollegen unseres Instituts basierend auf dem Neurobildgebungsdatensatz der UK Biobank, der zum Zeitpunkt des Projekts die Daten von etwa 42.000 Probanden umfasste, eine ganz besondere Prozessierungstechnik entwickelt. Für diese Technik haben sie ein System verwendet, das die gesamte Provenienz, also die Dokumentation darüber, woher das Datenmaterial stammt und mit welchen Prozessen und Methoden (Code, Softwaretools etc.) es verarbeitet wurde, erfasst. Eine solch detaillierte Dokumentation ist wichtig, um Reproduzierbarkeit zu ermöglichen. Die Besonderheit hier besteht darin, dass die Provenienz vom Computer ausgelesen und die vergangene Analyse automatisch wiederausgeführt werden kann, ohne mit den beteiligten Wissenschaftlern Rücksprache über die verwendeten Verarbeitungsschritte und deren Reihenfolge halten zu müssen. Das befähigt uns beispielsweise dazu, Analysen nach einer Erweiterung des zugrunde liegenden Datensatzes automatisch zu wiederholen oder die Reproduzierbarkeit unserer Ergebnisse zu prüfen.
Für die Entwicklung dieses Workflows haben unsere Wissenschaftler auf etablierte Softwarewerkzeuge aus Industrie und Wirtschaft (bspw. Git, HTCondor, SLURM) sowie lokal am Forschungszentrum Jülich entwickelte Software zum Datenmanagement (DataLad) zurückgegriffen. Dadurch werden Erkenntnisse aus der Industrie mit Erkenntnissen aus der Wissenschaft vereint, um unsere Forschung besonders reproduzierbar und skalierbar zu machen und dadurch insgesamt ihre Qualität zu steigern.
Als Grundlage für die Prozessierungstechnik haben unsere Wissenschaftler Software Container gewählt. Dies sind Softwareumgebungen, die ein minimales Betriebssystem und alle wichtigen Programme, die für eine Analyse benötigt werden, enthalten. In einem solchen Software Container können Analysen durchgeführt werden, ohne dass die notwendigen Programme auf dem Computer installieren sein müssen. Außerdem können sie mit anderen Personen geteilt werden, um ihnen die richtige Softwareumgebung einfach zur Verfügung zu stellen. Zum einen können dadurch für die Analyse auch nicht freiverfügbare Softwaretools genutzt werden und zum anderen sind die Analysen Hardware unabhängig, sodass Replikationsstudien nicht nur auf großen Supercomputern, sondern auch auf Laptops durchgeführt werden können.
Der gesamte Prozess ist komplett generisch, also auf alle möglichen Forschungsbereiche (wie z. B. Geowissenschaften, Politikwissenschaften, Wirtschaftswissenschaften etc.) anwendbar und nicht an bestimmte Datensätze, Analyseschritte, oder Softwaretools gebunden. Die Anwendung an einem so großen Datensatz, wie dem der UK Biobank, zeigt, dass das erstellte und öffentlich zur Verfügung gestellte Tool sehr gut auf wirklich große Datensätze anwendbar ist.
Zu Visualisierungszwecken haben unsere Kollegen ein Video erstellt, das eindrucksvoll die Dimension einer Datenanalyse dieses Ausmaßes und auch die immense Leistungsfähigkeit der rechnergestützten Infrastruktur, die am Forschungszentrum Jülich existiert, demonstriert: Zwischen Minute 00:20 und 01:20 ist die Analyse auf dem high-throughput compute cluster unseres Instituts visualisiert, und ab Minute 01:20 ist die Prozessierung auf dem Supercomputer JURECA dargestellt. Hier kommen Sie zum Video: https://www.youtube.com/watch?v=UsW6xN2f2jc
Um anderen Neurowissenschaftlern die Komplexität der Datenanalysen, die an unserem Institut durchgeführt werden, näher zu bringen, haben wir das Video bei der diesjährigen Brain Art Competition des alljährlichen Meetings der Organization for Human Brain Mapping (OHBM) eingereicht und in der Kategorie Video/Animation den zweiten Platz belegt!
Currently, no other topic influences our lives as much as COVID-19. Many shops are closed, events have been cancelled, social distancing is en vogue, etc. Wherever possible, home office has been set up to continue working as best as possible. This is the case in our institute as well.
The Forschungszentrum Jülich is very close to the Heinsberg district, one of the most affected areas in Germany. As the risk of virus spread is very high with around 6000 employees, important measures to contain it were taken at an early stage. Business trips were scaled down further and further, the canteen was closed, events with more than 40 people were prohibited and finally, basic operations were introduced.
In our institute, the Institute of Neuroscience and Medicine (INM-7), home office was already implemented at the beginning of March, which means that week 7 of home office is coming to an end. We have turned our lab completely virtual and luckily this has come with only minimal compromises in terms of science and supervision. After a short period of getting used to the new situation, everyone has become familiar with it.
In the current situation four new colleagues have started working in our institute. It is quite bizarre that they have already been working for a month, but have not been on site yet – but even that is feasible. Only for parents the situation is a bit more difficult, because they have to take care of their children besides their work.
In order to allow for social exchange, we have set up a virtual meeting room called INM-7 kitchen so that we don’t have to give up our common coffee break. We also meet every Tuesday evening for a social video conference while having a few drinks. Even our institute seminars can be held online, which works surprisingly well (given that more than 60 people are joining). Moreover, using virtual conferences, it is way easier to invite external speakers to our seminar. As a platform we use the app Zoom, but we want to switch to another one, because there are considerable security concerns. Once we tried “BigBlueButton”, but some colleagues had problems with it (at least when 60+ participants took part). Now we are looking for an alternative. Do you have any tips for us? Which app do you use and how well do you get along with it?
My conclusion after 7 weeks of home office: Fortunately, it is going surprisingly well and it is becoming more and more normal to work from home. Nevertheless, I’m really looking forward to finally meet my colleagues in real life again.
How about you? Are you doing home office and if so, how do you cope with that?
Stay healthy! Many greetings from our home offices
As the year 2019 slowly draws to a close, it is time to look back on the past 12 months.
During the last year, a lot of things happened in our institute. We started in January with approximately 41 colleagues and now we have grown to 63 colleagues. We have gained two new groups one is called “Psychoinformatics”, which focuses on the interface of neuroscience, psychology and computer science and the combination of classical experimental methodology with machine learning methods. This group is headed by Michael Hanke, who was appointed professor at the Heinrich Heine University Düsseldorf in the domain of Systematic Analysis of Brain Organization. The other one “Biomarker Development” led by Jürgen Dukart aims to identify, validate and integrate novel neuroimaging and digital biomarkers that can be applied for early detection and treatment evaluation of changes in brain organization in advanced age as well as in neurological and psychiatric diseases.
Psychoinformatics group led by Michael Hanke.
Biomarker Development group led by Jürgen Dukart.
At this point I would also like to mention that Anne Latz Anne successfully completed her doctorate with the title “Neural correlates of age-related changes in cognitive action control” this year. Moreover, Sofie Valk was selected as the winner of the SANS Poster Award for her poster on “Neurogenetic markers of personality” at the annual meeting of the Social & Affective Neuroscience Society in May.
With more than 40 published papers and highly future oriented topics our scientific development was enormous and very innovative this year. One of the most important topics is the use of machine-learning approaches to train predictive models for inference on phenotypical characteristics of new, individual subjects from brain imaging data. For example, Susanne Weis has found that the gender of subjects can be predicted by applying machine learning approaches to resting state data. Additionally, Ji Chen observed a new way of describing schizophrenia by the application of machine learning approaches. He identified a four-factor structure representing negative, positive, affective, and cognitive symptoms as the most stable and generalizable representation of psychopathology. In the next year we would like to investigate the application of machine learning and artificial intelligence even more to improve diagnosis and prognosis of psychiatric diseases.
A special highlight this year was the “Tag der Neugier” tat the Forschungszentrum, which gave more than 28,000 visitors the chance to take a look behind the scenes of research. At our institute, the guests were invited to perform several neuropsychological tests and personality questionnaires and compare their performance to those of others to find out what it feels like to be in such a neuropsychological testing situation. Moreover, from young to old, all visitors were fascinated by our inflatable brain, in which we gave talk and explained our research topics with posters. The absolute highlight, however, was the station where the visitors had to balance on a balance board while their movement parameters were measured using an app programmed by Jürgen Dukart’s group. Doing so, we wanted to show that smartphones and wearables record movements very sensitively and that this information can in turn be used as an objective tool for symptom evaluation and as a measure for disease progression. Below you can find a video that gives you an overview what happened at the Tag der Neugier at our institute.
I am very satisfied with the past year and hope that 2020 will be just as exciting, eventful and successful. Now I just want to wish you a Merry Christmas and a Happy New Year!
In June several colleagues of our institute visited the 25th Annual Meeting of the Organization for Human Brain Mapping (OHBM) in Rome. The aim of this international organization is to improve the understanding of the brain’s anatomical and functional organization by means of neuroimaging. Here, researchers from different domains like MRI, fMRI, PET, EEG/MEG and other cutting edge approaches such as electrophysiology, preclinical imaging, neuroepidemiology and genetics come together to present their research findings or methods by means of symposia, keynote lectures or posters. Moreover, especially for PhD students, educational courses and a hackathon are provided to promote education in human brain organization. With by now more than 4000 attendees, this conference belongs to one of the biggest ones in its field.
When I started my bachelor in psychology, I fell in love with the brain and its functions immediately. I was so passionate about it that next to my studies I engaged in voluntary internships and worked as a student assistant in several studies. I think that neuroscience is a highly interesting domain as researches have the opportunity to investigate their own scientific questions with the possibility to revolutionize our understanding of the human brain one day. However, what I realized during my studies is that most of the students were female whereas later on, higher positions are mainly engaged by men. Due to some underlying reasons it might be difficult for women to keep female majority with progressing career.
At the end of January, I had my first business trip to Berlin joining the VirtualBrainCloud kick-off meeting. Find out more about my personal experiences.